Introduction¶
MACE (Mobile AI Compute Engine) is a deep learning inference framework optimized for mobile heterogeneous computing platforms. MACE provides tools and documents to help users to deploy deep learning models to mobile phones, tablets, personal computers and IoT devices.
Architecture¶
The following figure shows the overall architecture.
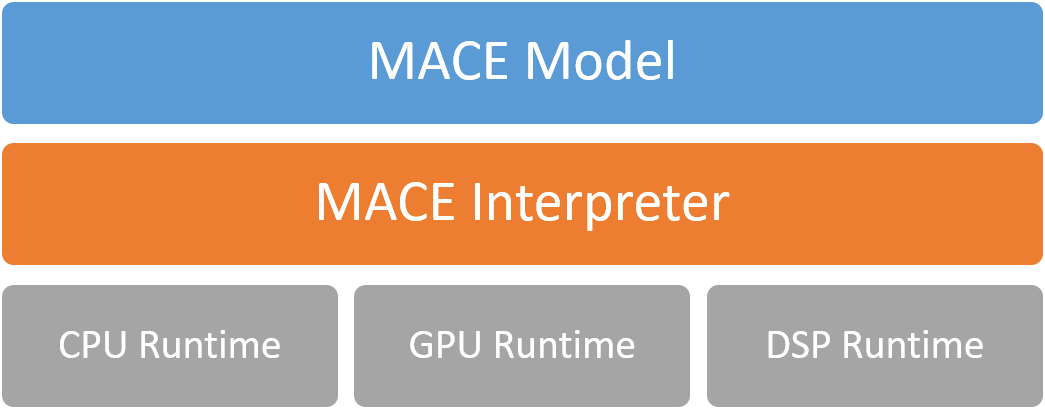
MACE Model¶
MACE defines a customized model format which is similar to Caffe2. The MACE model can be converted from exported models by TensorFlow, Caffe or ONNX Model.
MACE Interpreter¶
Mace Interpreter mainly parses the NN graph and manages the tensors in the graph.
Runtime¶
CPU/GPU/DSP runtime correspond to the Ops for different devices.
Workflow¶
The following figure shows the basic work flow of MACE.

1. Configure model deployment file¶
Model deploy configuration file (.yml) describes the information of the model and library, MACE will build the library based on the file.
2. Build libraries¶
Build MACE dynamic or static libraries.
3. Convert model¶
Convert TensorFlow, Caffe or ONNX model to MACE model.
4.1. Deploy¶
Integrate the MACE library into your application and run with MACE API.
4.2. Run (CLI)¶
MACE provides mace_run command line tool, which could be used to run model and validate model correctness against original TensorFlow or Caffe results.
4.3. Benchmark¶
MACE provides benchmark tool to get the Op level profiling result of the model.